Digitale Bilder und Bildkompression
In der Digitalfotographie werden Bilder als Bitmaps aufgenommen und dargestellt: als \(M\times N\) -Raster von quadratischen Bildelementen (Pixeln), wobei \(M\) die Breite und \(N\) die Höhe des Bildes in Pixeln ist.

Jeder einzelne Pixel kann \(2^b\) Werte annehmen, üblicherweise von \(0\) bis \(2^b-1\) für ein geeignetes \(b\in\mathbb{N}\) . Dabei wird \(b\) als Bittiefe bezeichnet und entspricht der Anzahl von Bits, die für die Speicherung der Information eines Pixels benötigt werden. Üblicherweise ist \(b=8\) , so dass jeder Pixelwert in genau einem Byte (8 Bits) gespeichert werden kann. Größere Bittiefen von 12, 14 oder 16 werden für höherwertige Fotographie und Druck oder Anwendungen in der Medizin und Astronomie verwendet.
Bei einer Bittiefe von 8 liegen Werte dann im Intervall [0,255], wobei in einem Graustufenbild 0 schwarz und 255 weiß entspricht.
Ein Farbbild hingegen setzt sich aus mehreren Pixelrastern zusammen, nämlich einem pro Farbkanal. Im Fall von RGB hat man also drei Pixelraster, jeweils eins für Rotwerte, eins für Grünwerte und eins für Blauwerte:
JPEG arbeitet mit dem Farbraum YCbCr, teilt die Informationen eines Bildes also in drei Kanäle auf: Y für die Grundhelligkeit, Cb für Chroma Blau (Farbintensität auf der Achse Blau-Gelb) und Cr für Chroma Rot (Farbintensität auf der Achse Rot-Grün).




Zerlegung eines Bildes in die einzelnen YCbCr-Kanäle. Oben links sieht man das Originalbild, oben rechts die Grundhelligkeit (Y), unten links die Blau-Gelb-Chroma (Cb) und unten rechts die Rot-Grün-Chroma (Cr).
Diese Darstellung von Bildern eignet sich allerdings schlecht für ihre Speicherung und Übertragung, da die Menge der dafür benötigten Daten vor allem bei höheren Auflösungen sehr umfangreich ist. Eine übliche Monitorauflösung von 1920x1200, zum Beispiel, entspricht einem Raster von 786.432 Pixeln. Bei einem Farbbild mit drei Kanälen sind das 2.359.296 Werte, für die je ein Byte benötig wird, man ist also bei einer Dateigröße von mehr als 2 MB. Bei Digitalkameras ist man schnell in der Größenordnung von 40 Megapixeln, was einer ungefähren Dateigröße von 115 MB pro Bild entspricht.
Um effizient mit Bilddaten arbeiten zu können, will man sie daher komprimieren, d.h. in eine kompaktere Darstellung überführen, die weniger Daten benötigt und dann zur Speicherung und Übertragung verwendet werden kann. Um das Bild schließlich wieder darzustellen, wird die komprimierte Darstellung zurück in ein Bildraster überführt.
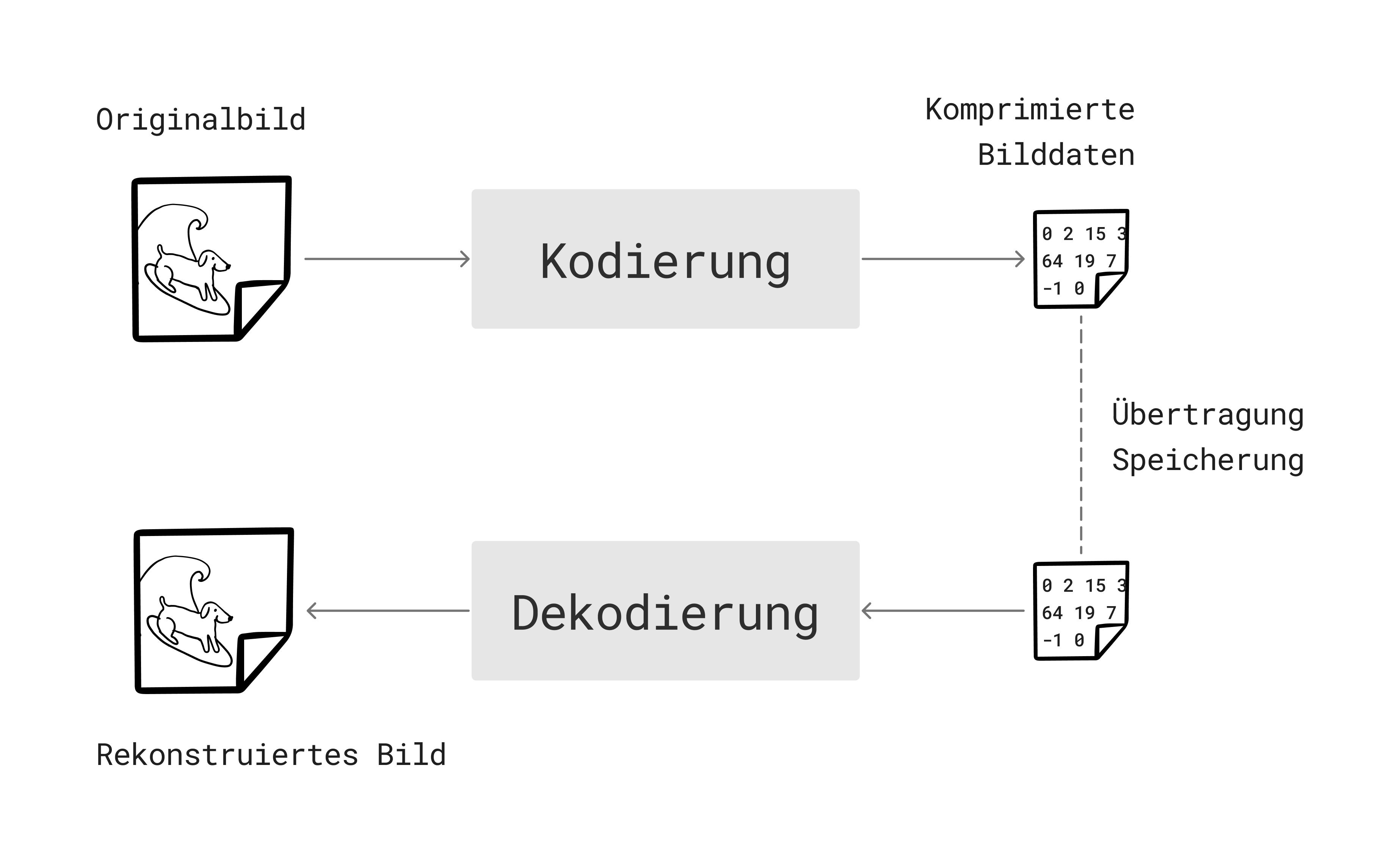
Bei einer verlustfreien Kompression ist die dekodierte Darstellung exakt die gleiche wie die ursprüngliche Darstellung vor der Kodierung, es gehen also keine Informationen verloren. Will man eine hohe Kompressionsrate erreichen, ist das allerdings oft nur mit einer verlustbehafteten Kompression möglich. Bei der Kodierung gehen dann Informationen verloren, die bei der Dekodierung nur annäherungsweise wieder hergestellt werden können; das rekonstruierte Bild entspricht also nicht exakt dem Originalbild.
Das Ziel bei der Bildkompression ist es nun, eine möglichst hohe Kompressionsrate bei möglichst guter Bildqualität zu erreichen, also möglichst wenig Informationen speichern oder übertragen zu müssen, ohne dass der Unterschied zwischen Originalbild und rekonstruiertem Bild visuell wahrnehmbar ist. JPEG ist ein sehr weit verbreiteter Kompressionsstandard, der genau das schafft: Das oben erwähnte Beispielbild von reichlich 2 MB benötigt als JPEG in guter Bildqualität nur noch ungefähr 0,2 MB.
Ein wesentlicher Teil des Algorithmus hinter JPEG besteht darin, das Bild zuerst in eine Darstellung zu transformieren, die im Gegensatz zum Pixelraster sehr effizient komprimiert werden kann. Dazu wird das Bildraster zuerst in Blöcke zerlegt. Jeden Block kann man als Vektor darstellen, der dann auf einen anderen Vektor angebildet wird, der die visuell relevanten Informationen in einen wenigen Elementen konzentriert (Diskrete Kosinustransformation). Alle anderen Elemente werden bei der Kompression dann fallengelassen (Quantisierung und Kodierung).
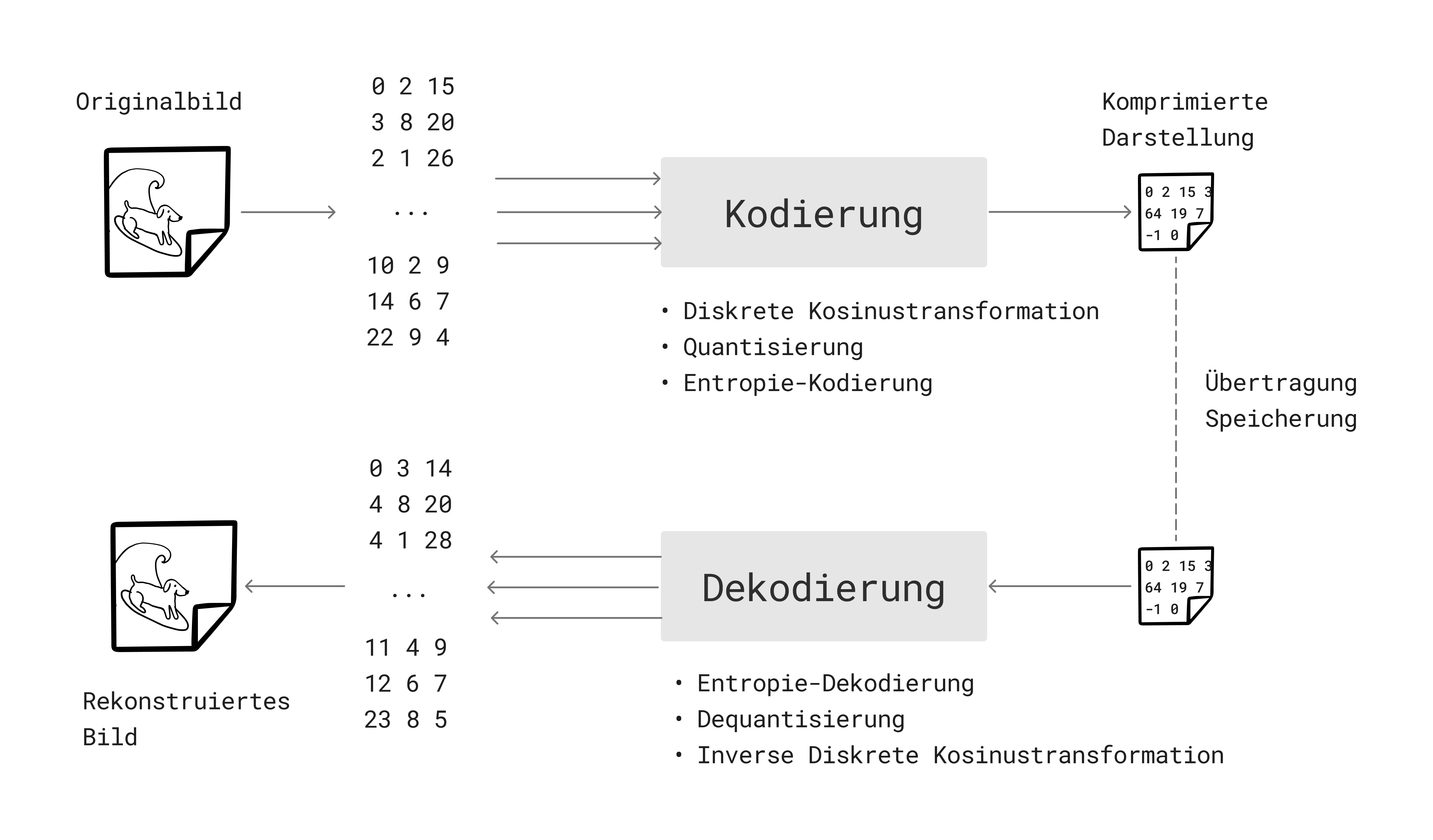
Im Fall eines Farbbildes werden die Farbkanäle prinzipiell gleich verarbeitet, man kann aber die Kompressionsrate für jeden Farbkanal unterschiedlich wählen. Zum Beispiel ist die menschliche Wahrnehmung sehr viel sensitiver für Grundhelligkeit als für Chroma, weswegen man für den Y-Kanal eine höhere Abtastrate und geringere Kompressionsrate wählt, während man für Cb und Cr mit einer geringeren Abtastrate und größeren Kompressionsrate davonkommt.
Vektordarstellungen von Pixelrastern
Wir wollen im Folgenden nur einen Kanal betrachten, also entweder ein Graustufenbild oder nur einen der Kanäle eines Farbbildes. Mathematisch ist es egal, welchen wir wählen, da alle Kanäle mit denselben \(2^b\) Werten arbeiten und in Bezug auf die hier betrachteten Transformationsschritte gleich behandelt werden.
Der erste Schritt bei der JPEG-Kompression ist ein sogenannter Level Shift, der die Werte mithilfe einer Abbildung von \([0,2^b - 1]\) auf \([-2^{b-1},2^{b-1} - 1]\) so verschiebt, dass die 0 zentriert ist; im Fall von \(b=8\) von [0,255] auf [-127, 128].
Außerdem wird nicht mit dem Bildraster als Ganzem gearbeitet. Statt dessen wird das Raster zunächst in 8x8-Blöcke zerlegt. (Ist die Höhe oder Breite des Bildes nicht durch 8 teilbar, wird das Pixelraster um entsprechend viele Reihen oder Spalten erweitert, die am Ende wieder entfernt werden.) Alle Verarbeitungsschritte werden getrennt auf jeden dieser Blöcke angewendet.
Solche 8x8-Blöcke lassen sich mathematisch als 8x8-Matrix darstellen - oder einfacher als 64-elementige Vektoren, also Elemente im Raum \(\mathbb{R}^{64}\) . (Im Prinzip reicht hier auch \(\mathbb{Z}^{64}\) , aber für die Koeffizientendarstellung später brauchen wir reelle Werte.)
Der Einfachheit halber betrachten wir aber vorerst nur eine Dimension, nur die Zeilen der Blöcke, d.h. Vektoren im \(\mathbb{R}^{8}\) . Die Erweiterung auf zwei Dimensionen ist am Ende unkompliziert.
Vektor als Linearkombination bezüglich der kanonischen Basis
Die kanonische Basis des \(\mathbb{R}^{8}\) ist:
$$e_1 = \begin{pmatrix}1 & 0 & 0 & 0 & 0 & 0 & 0 & 0\end{pmatrix}$$ $$e_2 = \begin{pmatrix}0 & 1 & 0 & 0 & 0 & 0 & 0 & 0\end{pmatrix}$$ $$\vdots$$ $$e_8 = \begin{pmatrix}0 & 0 & 0 & 0 & 0 & 0 & 0 & 1\end{pmatrix}$$
Eine Zeile eines 8x8-Blocks eines Bildrasters kann als eine Linearkombination dieser Einheitsvektoren dargestellt werden.
$$\begin{pmatrix}121 & 127 & 128 & 125 & 88 & 14 & -40 & -60\end{pmatrix}$$ $$= 121\,e_1 + 127\,e_2 + 128\,e_3 + 125\,e_4 + 88\,e_5 + 14\,e_6 - 40\,e_7 - 60\,e_8$$
Da die genaue Abmessung der Blöcke keine Rolle spielt, werden wir im Folgenden allgemein von Vektoren im \(\mathbb{R}^{N}\) reden (und im zweidimensionalen Fall dann schießlich im \(\mathbb{R}^{N\cdot N}\) ).
Eine Vektordarstellung bezüglich der kanonischen Basis erfasst die räumliche Verteilung von Graustufen- bzw. Farbwerten. Sie hat allerdings einen entscheidenden Nachteil: Sie lässt sich nur schwer komprimieren, da die für das Bild wichtigen Informationen wenig Redundanzen aufweisen, über den gesamten Vektor verteilt sind und diese Verteilung keinen statistischen Gleichmäßigkeiten folgt.
Die Grundidee des JPEG-Standards ist deswegen, den räumlichen Vektor in einem ersten Schritt auf einen Vektor abzubilden, der die für die menschliche Wahrnehmung wesentlichen Informationen des Bildes in einigen wenigen Elementen konzentriert. Die restlichen Elemente, die visuell weniger gut wahrnehmbare Informationen erfassen, können dann bei der Kompression verlorengehen. Dadurch lässt sich die Menge der zu speichernden Informationen deutlich verringern, während der Informationsverlust bei der Rekonstruktion des Bildes kaum sichtbar ist.
Diese Transformation selber komprimiert aber noch nicht; das Ziel ist lediglich eine Darstellung des Bildes zu erhalten, die sich im nächsten Schritt gut komprimieren lässt, ohne die Qualität des rekonstruierten Bildes wahrnehmbar zu beeinträchtigen.
Vektor als Stützstellendarstellung einer kontinuierlichen Funktion
Bisher haben wir einen Vektor \(p = \begin{pmatrix} p_0 & p_1 & \ldots & p_{N-1}\end{pmatrix}\) in \(\mathbb{R}^{N}\) bezüglich der kanonischen Basis. Einen solchen Vektor können wir als Stützstellendarstellung einer kontinuierlichen, stetigen Funktion \(f\) verstehen. Das bedeutet, dass der Vektor \(p\) für \(i = 0,\ldots, N-1\) genau die Funktionswerte \(p_i = f(x_i)\) der Funktion an den Stützstellen \(x_0,\ldots,x_{N-1}\) enthält.
Im Fall unseres Beispielvektors \(\begin{pmatrix}121 & 127 & 128 & 125 & 88 & 14 & -40 & -60\end{pmatrix}\) kennen wir also folgende Werte an den Stützstellen \(i=0,\ldots,7\) .
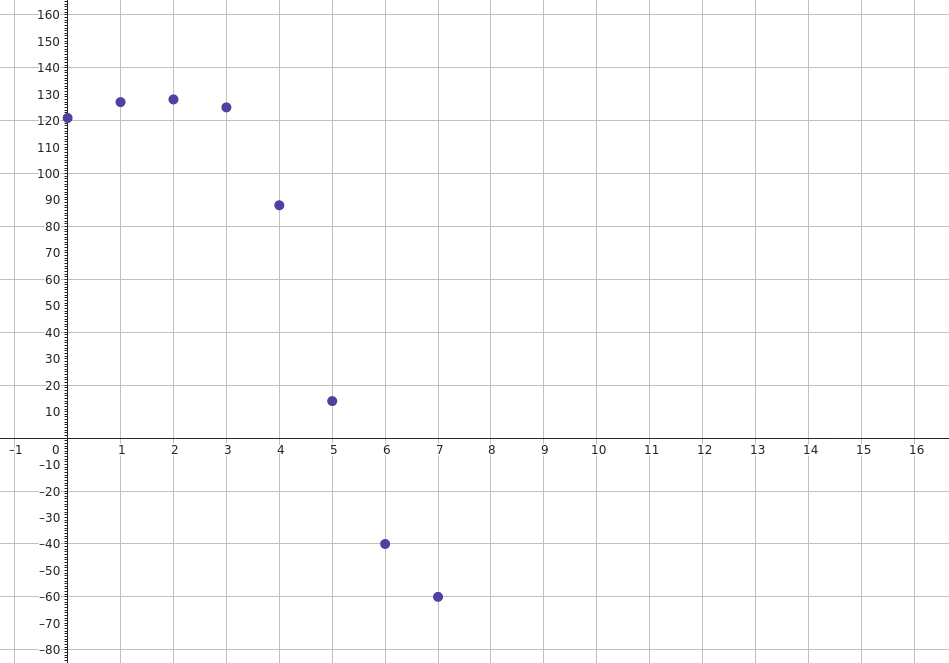
Bekannt sind also nur \(N\) Werte der Funktion \(f\) in einem beschränkten Intervall. Um die Menge der möglichen Funktionen, die diese Werte durchlaufen, so weit einzuschränken, dass wir praktisch damit weiterarbeiten können, treffen wir ein paar zusätzliche Annahmen.
Zunächst nehmen wir an, dass die zugrundeliegende kontinuierliche Funktion \(f\) periodisch ist, mit einer Periode von \(2N\) , so dass unsere bisherige Stützstellendarstellung \(p\) genau eine halbe Phase dieser periodischen Funktion abdeckt. Eine Fortsetzung der Funktion erhalten wir, indem wir die gebenenen Werte zu beiden Seiten unseres Intervalls spiegeln. Hier gibt es mehrere Möglichkeiten; für JPEG relevant ist eine Spiegelung achsensymmetrisch zur y-Achse in den Punkten zwischen den Stützstellen. Wir erweitern die Funktion also in beide Richtungen als gerade Funktion, d.h. so dass \(f(-x)=f(x)\) , und so dass sich die Randpunkte unseres ursprünglichen Vektors wiederholen.
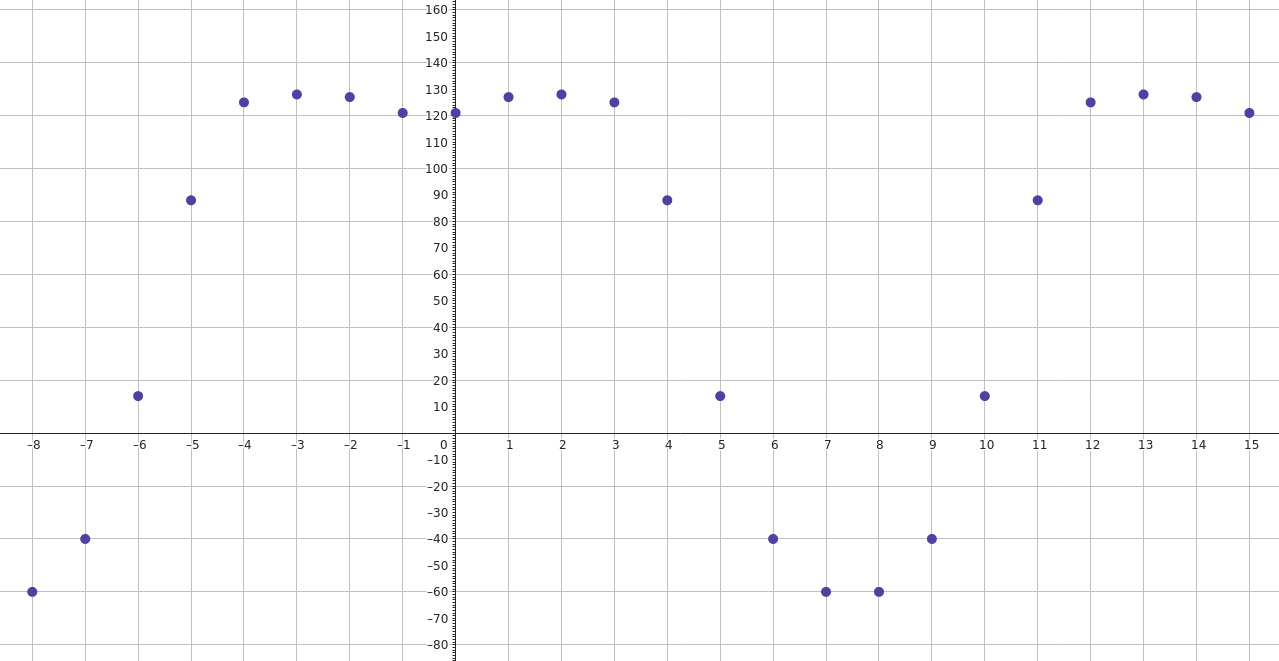
Wir nehmen also an, dass unser diskreter Vektor \(p\) die Werte einer kontinuierlichen, periodischen, geraden Funktion \(f:\mathbb{R}\to\mathbb{R}\) an \(N\) Stützstellen darstellt.
Vektor als Koordinatendarstellung bezüglich Kosinusbasisfunktionen
Die zugrundeliegende Funktion kennen wir nicht genau, aber aufgrund der über diese Funktion getroffenen Annahmen wissen wir, dass sie als Reihe von gewichteten Kosinusfunktionen dargestellt werden kann (mit Koeffizienten \(c_k\in\mathbb{R}\) ): $$f(x) = \sum_{k=0}^\infty c_k\cos(kx)$$
Für unseren Anwendungsfall interessiert uns allerdings nicht die ganze Reihe. Da wir eine endliche Darstellung, idealerweise wieder eine Vektordarstellung im \(\mathbb{R}^N\) , suchen, beschränken wir uns auf die \(N\) -elementige Partialsumme \(\sum_{k=0}^{N-1} c_k\cos(kx)\) . Wir approximieren die zugrundeliegende Funktion \(f\) also durch ein trigonometrisches Polynom.
Wo genau liegen nun die Stützstellen? Da \(\cos(x)\) eine Periode von \(2\pi\) hat, wir aber eine Periode von \(2N\) Einheiten annehmen, sind die Abschnitte von einer Stützstelle zur nächsten \(\frac{2\pi}{2N}=\frac{\pi}{N}\) groß (die sogenannte Kreisfrequenz). Die Stützstellen werden außerdem um \(\frac{1}{2}\) phasenverschoben und sind statt \(i\frac{\pi}{N}\) demnach \((i+\frac{1}{2})\frac{\pi}{N}\) .
Damit die Kosinusfunktionen \(\cos(kx)\) als Basis unserer Vektordarstellung im \(\mathbb{R}^N\) dienen können, wollen wir sie zusätzlich normalisieren. Dazu skalieren wir sie um folgenden Faktor \(s_k\) : $$s_k = \begin{cases} \sqrt{\frac{1}{N}} & \text{wenn } k=0 \\ \sqrt{\frac{2}{N}} & \text{sonst} \end{cases}$$
Wir definieren also für Wellenzahlen \(k\in\{0,1,\ldots,N-1\}\) und \(i\in\{0,1,\ldots,N-1\}\) die Basisfunktionen und Stützstellen wie folgt:
$$\text{Basisfunktionen}\colon b_k(x_i)=s_k \cos\left( k x_i \right)$$ $$\text{Stützstellen}\colon x_i = (i+\frac{1}{2}) \frac{\pi}{N}$$
Setzt man die Stützstellen ein, ergibt sich:
$$b_k(x_i)=s_k\cos\left(k\,(i+\frac{1}{2})\frac{\pi}{N}\right) = s_k\cos\left(\frac{(2i+1)k\,\pi}{2N}\right)$$Für \(N=8\) sehen die Funktionen und Stützstellen damit wie folgt aus. (Die Funktionswerte der Basisfunktionen \(b_k\) an den Stützstellen \(x_i\) werden am Ende unsere neuen Basisvektoren.)
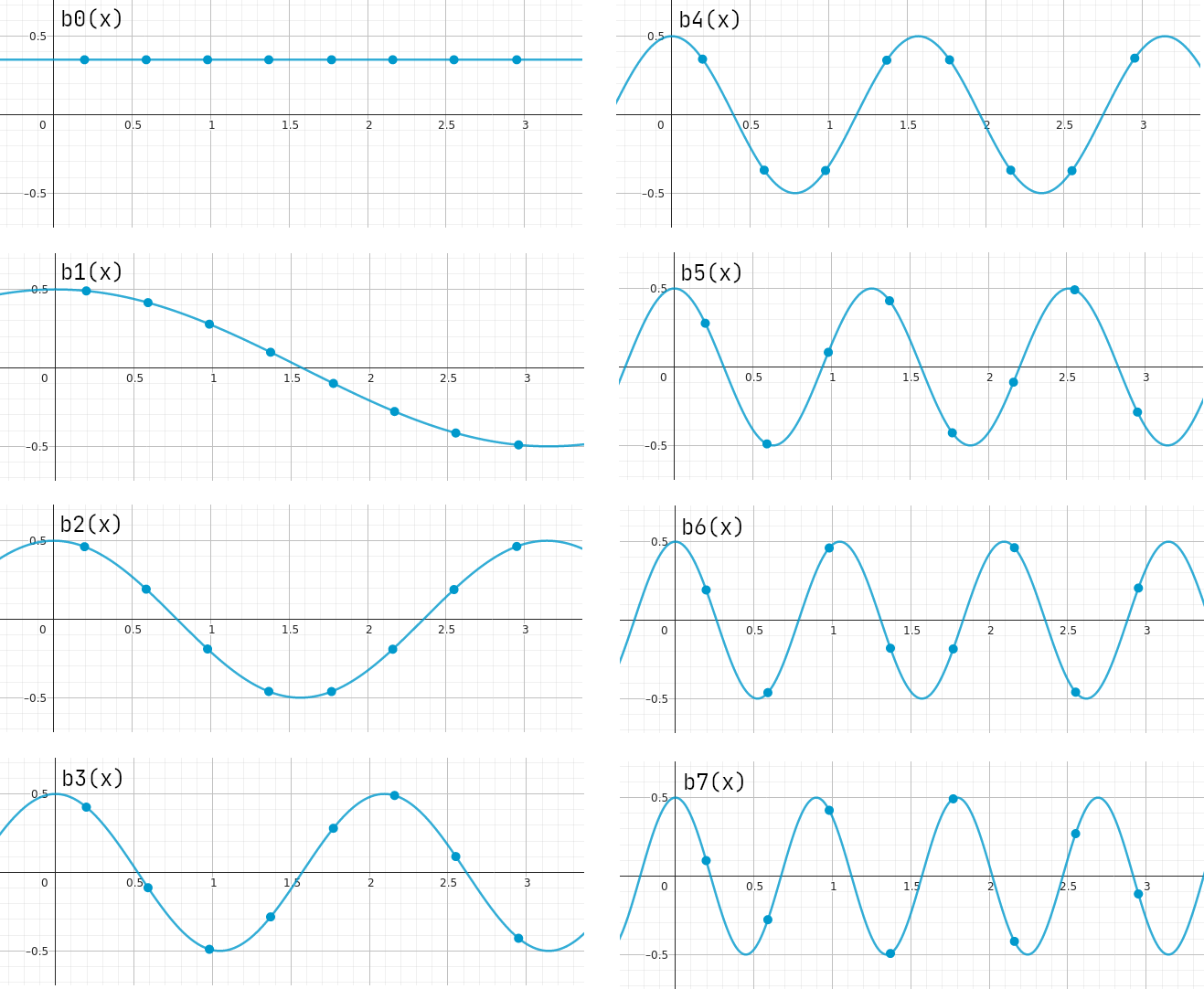
Die Funktionswerte \(f(x)\) der Funktion, die unserem Stützstellenvektors zugrundeliegt, lassen sich also als Linearkombination der Basisfunktionen darstellen, mit Koeffizienten \(c_k\in\mathbb{R}\) : $$f(x) \sim c_0 b_0(x) + c_1 b_1(x) + \ldots + c_{N-1} b_{N-1}(x) = \sum_{k=0}^{N-1}c_k s_k \cos(kx)$$
Bei Audiosignalen ist die Intuition hinter einer solchen Darstellung, dass das Signal in Grundschwingungen verschiedener Frequenzen zerlegt werden kann. Bei Bildern hingegen kann man die Basisfunktionen als Kontraste mit steigender Frequenz verstehen (siehe MathWorks' grafische Darstellung der Basisfunktionen). Die Linearkombination gibt dann an, welche Kontraste zu welchem Anteil im Bildraster vorkommen, wobei ein großer Koeffizientenwert bedeutet, dass der Kontrast stark ausgeprägt ist, die Unterschiede zwischen benachbarten Pixeln also relativ groß sind.
{kind=link}
Für den Anwendungsfall der Kompression interessieren uns nur die Koeffizienten, da die Basisfunktionen fix sind und nicht als Information mit gespeichert und übertragen werden müssen. Die Koordinatendarstellung liefert uns damit eine weitere diskrete Darstellung der Bildinformation: Neben der ursprünglichen Stützstellendarstellung eines Pixelrasters $$p=\begin{pmatrix} p_0 & \ldots & p_{N-1} \end{pmatrix}$$ wo die Elemente \(p_i\) die Graustufen- oder Farbwerte an dem räumlichen Index \(i\) sind, haben wir eine Koeffizientendarstellung $$c=\begin{pmatrix} c_0 & \ldots & c_{N-1} \end{pmatrix}$$ Die Vektorelemente in \(c\) haben dabei keine räumliche Bedeutung mehr. Entscheidend ist, dass sich in der Koeffizientendarstellung \(c\) die visuell wichtigen Information des Bildes in einigen wenigen Koeffizienten konzentriert. Die Koeffizientendarstellung erlaubt es also prinzipiell, sehr viel mehr Informationen wegzuwerfen als die Stützstellendarstellung, ohne einen deutliche Informationsverlust zu erleiden.
Um das für die Bildkompression ausnutzen zu können, brauchen wir aber noch eine Abbildung von \(p\) auf \(c\) und umgekehrt.
Diskrete Kosinustransformation
Bisher haben wir zwei Vektordarstellungen in \(\mathbb{R}^N\) betrachtet: eine Darstellung \(p\) bezüglich der kanonischen Basis, die wir als Stützstellendarstellung einer zugrundeliegenden Funktion \(f\) interpretiert haben, und eine Koordinatendarstellung \(c\) von \(f\) bezüglich einer Basis von Kosinusfunktionen verschiedener Frequenzen. Die Darstellung \(c\) stellt sich dabei als sehr viel besser komprimierbar heraus. Um das nutzen zu können, brauchen wir eine Abbildung von der Stützstellendarstellung \(p\) auf die Koeffizientendarstellung \(c\) und umgekehrt. Beide Darstellungen sind Vektoren im Raum \(\mathbb{R}^N\) und wir werden sehen, dass die Abbildung zwischen ihnen einem Basiswechsel entspricht.
Betrachten wir zuerst die Abbildung eines Koeffizientenvektors \(c\) auf den entsprechenden Stützstellenvektor \(p\) . Dazu berechnen wir den Funktionswert \(f(x_i)\) (eine Linearkombination der Basisfunktionen \(b_k\) ) an den einzelnen Stützstellen \(x_i\) durch Einsetzen:
(1) $$f(x_i) = \sum_{k=0}^{N-1}c_k b_k = \sum_{k=0}^{N-1}c_k s_k\cos(k x_i) = \sum_{k=0}^{N-1}c_k\,s_k \cos(k\,(i+\frac{1}{2})\frac{\pi}{N})$$
Die Funktionswerte \(f(x_i)\) bilden die Elemente des Vektors \(p=\begin{pmatrix} p_0 & \ldots & p_i & \ldots & p_{N-1} \end{pmatrix}\) , der sich also wie folgt zusammensetzt:
$$p_0 = f(x_0) = c_0b_0(x_0) + c_1b_1(x_0) + \ldots + c_{N-1}b_{N-1}(x_0)$$ $$\ldots$$ $$p_i = f(x_i) = c_0b_0(x_i) + c_1b_1(x_i) + \ldots + c_{N-1}b_{N-1}(x_i)$$ $$\ldots$$ $$p_{N-1} = f(x_{N-1}) = c_0b_0(x_{N-1}) + c_1b_1(x_{N-1}) + \ldots + c_{N-1}b_{N-1}(x_{N-1})$$
Der Vektor \(p\) ist demnach das Produkt aus dem Koeffizientenvektor \(c=\begin{pmatrix} c_0 & c_1 & \ldots & c_{N-1} \end{pmatrix}\) und einer Matrix mit den Basisfunktionen als Elemente, die wir \(T\) nennen:
(2) $$p = c\cdot T = \begin{pmatrix} c_0 & c_1 & \ldots & c_{N-1} \end{pmatrix} \cdot \begin{pmatrix} b_0(x_0) & b_0(x_1) & \ldots & b_0(x_{N-1}) \\ \vdots & \vdots & & \vdots \\ b_i(x_0) & b_i(x_1) & \ldots & b_i(x_{N-1}) \\ \vdots & \vdots & & \vdots \\ b_{N-1}(x_0) & b_{N-1}(x_1) & \ldots & b_{N-1}(x_{N-1}) \end{pmatrix}$$
Die Elemente der Matrix \(T\) sind also:
$$T_{ij} = b_i(x_j) = s_i \cos(i\cdot(j+\frac{1}{2})\cdot\frac{\pi}{N}) = \begin{cases} \sqrt{\frac{1}{N}} & \text{ falls } i = 0 \\ \sqrt{\frac{2}{N}}\cos(i\cdot(j+\frac{1}{2})\cdot\frac{\pi}{N}) & \text{ sonst }\end{cases}$$Die Matrix \(T\) ist orthogonal, d.h. ihre Spaltenvektoren \(t_k,t_l\) sind normalisiert und paarweise orthogonal bezüglich dem Standardskalarprodukt des \(\mathbb{R}^N\) : $$\langle t_k,t_l\rangle = t_k^\top t_l= \sum_{n=0}^{N-1} t_{kn} t_{ln} = \begin{cases} 1 & \text{ falls } k=l \\ 0 & \text{ sonst} \end{cases}$$
Die Spaltenvektoren von \(T\) sind demnach linear unabhängig und bilden eine Orthonormalbasis von \(\mathbb{R}^N\) . Die Matrix \(T\) selber ist also eine Basiswechselmatrix. Aus der Orthogonalität von \(T\) folgt, dass sie invertierbar ist, wobei die Inverse \(T^{-1}\) gleich der Transponierten \(T^\top\) ist.
Aus \(p = c\cdot T\) folgt daher \(p\cdot T^{-1} = c\) und damit auch \(p\cdot T^\top = c\) , d.h.:
(3) $$c = \begin{pmatrix} p_0 & \ldots & p_i & \ldots & p_{N-1} \end{pmatrix} \cdot \begin{pmatrix} b_0(x_0) & b_1(x_0) & \ldots & b_{N-1}(x_0) \\ \vdots & \vdots & & \vdots \\ b_0(x_i) & b_1(x_i) & \ldots & b_{N-1}(x_i) \\ \vdots & \vdots & & \vdots \\ b_0(x_{N-1}) & b_1(x_{N-1}) & \ldots & b_{N-1}(x_{N-1}) \end{pmatrix}$$
Daraus ergeben sich die Koeffizienten, die die Vektorelemente von \(c\) bilden, wie folgt:
(4) $$c_i = p_0\,b_i(x_0) + p_1\,b_i(x_1) + \ldots + p_{N-1}\,b_i(x_{N-1})$$ $$= \sum_{k=0}^{N-1} p_k\,b_i(x_k)$$ $$= \sum_{k=0}^{N-1} p_k\,s_i \cos(i\cdot(k+\frac{1}{2})\cdot\frac{\pi}{N})$$
Mit (2) und (3) haben wir Abbildungen \(\mathbb{R}^{N}\to\mathbb{R}^{N}\) zwischen \(p\) und \(c\) , die Diskrete Kosinustransformation II genannt werden.
1D
Im eindimensionalen Fall definiert man die Abbildung \(p\mapsto c\) und ihre Inverse \(c\mapsto p\) üblicherweise als Formel, um aus den Elementen von \(p\) die Elemente von \(c\) zu berechnen und umgekehrt. Diese Formeln ergeben sich direkt aus (1) und (4), nur unter Umbenennung von Indizes, wobei \(i,\in\{0,\ldots,N-1\}\) jeweils Vektorindizes sind:
$$p_i = \sum_{k=0}^{N-1}c_k\,s_k\cos(k\cdot(i+\frac{1}{2})\cdot\frac{\pi}{N})$$ $$c_k = \sum_{i=0}^{N-1}p_i\,s_k\cos(k\cdot(i+\frac{1}{2})\cdot\frac{\pi}{N})$$
2D
Der zweidimensionale Fall lässt sich auf den eindimensionalen Fall zurückführen, indem beide Dimensionen getrennt transformiert werden. Das Bildraster \(P\) ist eine \(N\times N\) -Matrix, deren Zeilenvektoren die Vektoren \(p\) sind. Zunächst werden diese Zeilenvektoren eindimensional transformiert, indem man sie mit \(T^\top\) multipliziert. Das Ergebnis ist eine \(N\times N\) -Matrix \(A = P\cdot T^\top\) . Um die Spalten auf die gleiche Weise zu transformieren, transponiert man diese Matrix \(A\) , multipliziert sie erneut mit \(T^\top\) und transponiert sie anschließend wieder zurück. Das Ergebnis ist die Matrix \(C=(A^\top\cdot T^\top)^\top = T\cdot A\) , deren Elemente nun Koeffizienten sind. Aus \(C = T\cdot A\) und \(A = P\cdot T^\top\) ergibt sich direkt, dass: $$C = T\cdot P\cdot T^\top$$
Die zweidimensionale Formel für die Berechnung von Elementen \(C_{ij}\) der Koeffizientenmatrix aus Elementen \(P_{xy}\) der Bildmatrix und umgekehrt entspricht dann einer Hintereinanderausführung der entsprechenden eindimensionalen Formeln, wobei \(i,j,x,y\in\{0,\ldots,N-1\}\) jeweils Vektorindizes sind:
$$P_{xy} = \sum_{i=0}^{N-1}\sum_{j=0}^{N-1} C_{ij}\,s_x\, s_y\, \cos(x\cdot(i+\frac{1}{2})\cdot\frac{\pi}{N})\, \cos(y\cdot(j+\frac{1}{2})\cdot\frac{\pi}{N})$$ $$C_{ij} = \sum_{x=0}^{N-1}\sum_{y=0}^{N-1} P_{xy}\,s_x\, s_y\, \cos(x\cdot(i+\frac{1}{2})\cdot\frac{\pi}{N})\, \cos(y\cdot(j+\frac{1}{2})\cdot\frac{\pi}{N})$$
Da die Basisfunktionen im Voraus berechnet werden können, ist die Transformation insgesamt effizient berechenbar.
Beispiel
Betrachten wir das Pixelraster vom Beginn:
Nach Anwendung der Diskreten Kosinustransformation bekommen wir ein Raster von Koeffizienten, in dem sich große Werte vor allem links oben konzentrieren:
$$\begin{array}{rrrrrrr} 441.4 & 313.7 & -10.6 & 27.5 & -6.5 & -2.6 & 0.4 & -4.0 \\ 539.2 & -236.3 & -61.2 & -11.5 & -5.6 & 5.4 & -0.3 & 5.0 \\ -175.5 & -86.2 & 124.0 & 3.4 & 9.1 & -3.6 & 0.9 & -2.7 \\ 17.8 & 136.7 & -30.0 & -42.8 & 5.4 & -8.3 & 3.5 & 0.0 \\ -26.1 & -44.0 & -45.2 & 23.8 & 11.0 & 0.6 & -3.0 & 1.8 \\ 20.6 & 20.0 & 16.4 & 21.1 & -16.4 & 1.3 & 0.4 & -4.1 \\ -12.3 & -17.8 & -2.9 & -8.3 & -9.2 & 5.3 & 2.1 & 5.0 \\ 8.5 & 3.8 & 9.5 & -11.3 & 15.8 & -3.1 & -5.9 & -0.2 \end{array}$$Der Informationsverlust passiert nun im nächsten Schritt der Quantisierung. Das Ziel ist es, Koeffizienten nur so präzise wie nötig zu speichern. Kleine Koeffizienten, zum Beispiel, spielen für die visuelle Wahrnehmung kaum eine Rolle. Dazu werden nun alle Koeffizienten \(C_{ij}\) mit einer Schrittgröße \(Q_{ij}\) geteilt und ganzzahlig gerundet:
$$C'_{ij}=\text{round}_\text{int}(\frac{C_{ij}}{Q_{ij}})$$Die Schrittwerte werden einer Quantisierungstabelle entnommen und bestimmen, wie groß der Informationsverlust und damit auch die Kompressionsrate (und letztendlich die Bildqualität) ist. Intuitiv entspricht die Schrittgröße einem Wahrnehmungsschwellwert: bis zu welchem Koeefizienten man den Beitrag der entsprechenden Basisfunktion visuell wahrnehmen kann.
Je nachdem, welche Tabelle des JPEG-Standards man anwendet, ergeben sich zum Beispiel diese Raster:
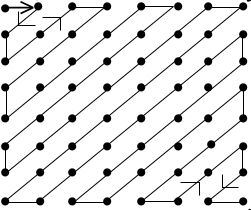
$$\begin{array}{r} 28 & 29 & -1 & 2 & 0 & 0 & 0 & 0 \\ 45 & -20 & -4 & 0 & 0 & 0 & 0 & 0 \\ -13 & -7 & 8 & 0 & 0 & 0 & 0 & 0 \\ 1 & 8 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 6 & 0 & 0 & 0 & 0 & 0 & 0 \\ -1 & -1 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \end{array} \qquad \begin{array}{r} 26 & 17 & 0 & 0 & 0 & 0 & 0 & 0 \\ 30 & -11 & -2 & 0 & 0 & 0 & 0 & 0 \\ -7 & -3 & 2 & 0 & 0 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \end{array}$$Ordnet man diese Werte nun nach folgendem Muster, bekommt man eine Reihe, in der die Elemente so geordnet sind, dass die von Null verschiedenen Elemente am Anfang stehen und man einen Großteil der Information nicht mehr speichern muss.
Um die Quantisierung beim Dekodieren wieder rückgängig zu machen, multipliziert man die Werte mit der Schrittgröße: \(C_{ij}=C'_{ij}Q_{ij}\) . Die Koeffizientenraster, die man so rekonstruiert, entsprechen aufgrund des Informationsverlustes nicht exakt den ursprünglichen Koeffizienten, aber rekonstruiert man daraus wieder ein Pixelraster, ist der Unterschied visuell nur bei hoher Kompressionsrate sichtbar.
Zumindestens gilt das für natürliche Bilder, wo Übergänge auf Pixelebene fließend sind. Denn die Quantisierungstabellen gehen von der Annahme aus, dass sehr harte Übergänge von einem Pixel zum nächsten nicht vorkommen. Ist das in einer Bitmap der Fall, z.B. bei Textdokumenten, dann sind die Informationen gleichmäßiger über die Koeffizienten verteilt, was dazu führt, dass bei der Kompression fälschlicherweise auch für die Wahrnehmung relevante Informationen weggeworfen werden, was dann sichtbare Fehler bei der Rekonstruktion (sogenannte JPEG-Artefakte) zur Folge hat.
Referenzen
Berner, Julius: Diskrete Kosinustransformation in der Bildverarbeitung. BSc Thesis, Universität Wien, 2016.
Burger, Wilhelm und Mark James Burge: Digitale Bildverarbeitung. Springer eXamen.press, 2006.
Pound, Mike: Discrete Cosine Transform (JPEG Pt2). YouTube, 2015.
Lang, Hans Werner: Diskrete Cosinus-Transformation (DCT). Hochschule Flensburg, 2005.
Wallace, Gregory K. The JPEG Still Picture Compression Standard. IEEE Transactions on Consumer Electronics, 38(1), 1992.